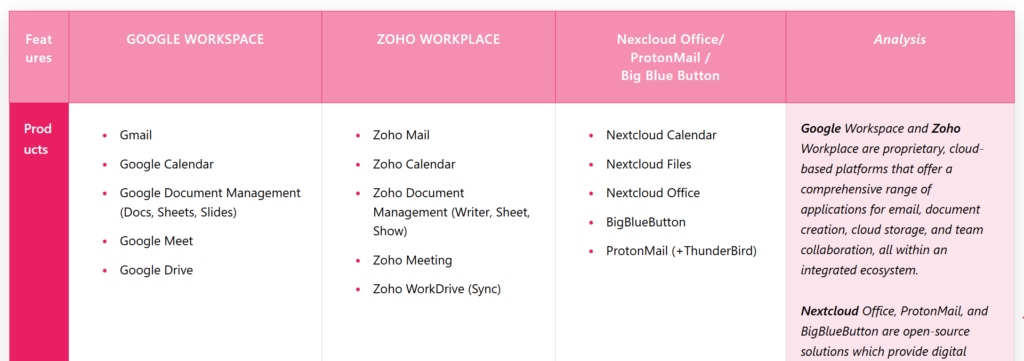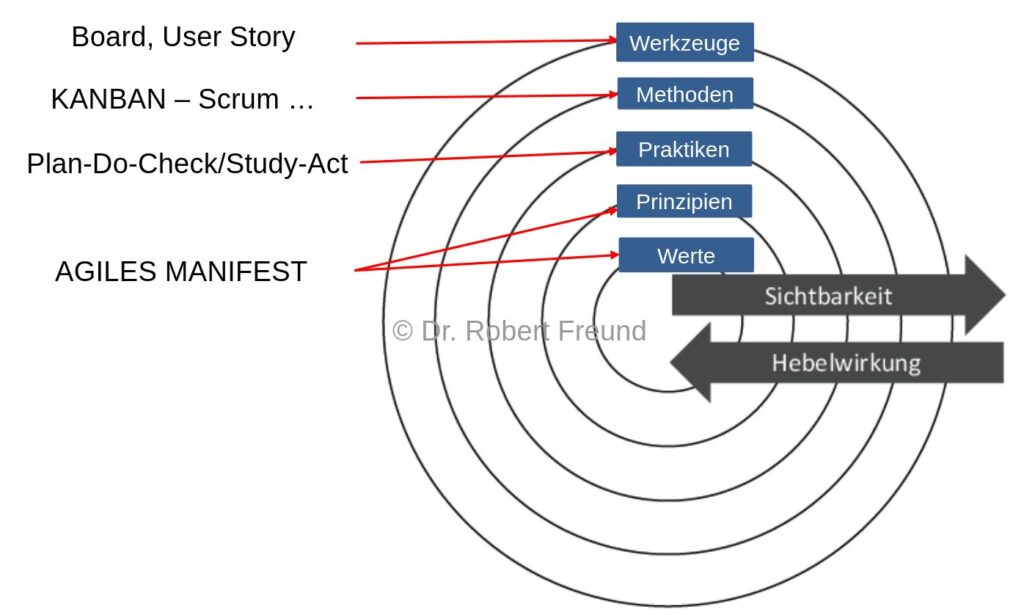
Das Zwiebelmodell (Abbildung) zeigt den Zusammenhang einzelner Begriffe im agilen Umfeld und deren jeweilige Wirkung. Je näher der Begriff am inneren Kreis positioniert ist, je größer ist seine Hebelwirkung. Ist ein Begriff am äußeren Rand der Abbildung positioniert, so bedeutet das eine größere Sichtbarkeit.
Werte und Prinzipien haben also eine große Hebelwirkung. Konkrete Hinweise dazu findet man in dem Agilen Manifest. Praktiken, Methoden und Werkzeuge sind oft in der Praxis zu sehen, basieren allerdings alle auf den Werten und Prinzipien.
Scrum wird hier als Methode gekennzeichnet, sollte allerdings eher als Framework (Rahmenwerk) bezeichnet werden.
Aktuell konzentrieren sich viele Organisationen noch zu stark auf Werkzeuge, Methoden und Praktiken, ohne ihre organisationalen Werte und Prinzipien anzupassen.
Mehr Beiträge zur Agilen Organisation finden Sie hier.